






きのこの山とたけのこの里を分類するAIを作ってみようと思います。
今回はPythonにて物体検出の機械学習アルゴリズムで有名なYOLO3を利用して行います!
実は、少し前に同じ実験を行ったのですが、
合っていない学習モデルで行ってしまったために散々な結果で終わりました。
今回は、その失敗から勉強をし直し、再挑戦していく過程を記録していきます。
物体検出の精度をあげるために
前回の反省をもとに、勉強して、下記の点を注意することにしました。
①実際の状況に合わせた学習データを集める
前回は、Web上から適当に集めた画像を使わせていただきました。
しかし、実際の現場で、撮影してAIに送る画像は当然異なります。
撮影する状況(ユーザーが利用する状況)を想定した学習データの用意を意識しました。
②画像サイズをリサイズして、統一する
前回は、Web上の画像をそのまま利用して学習したため、画像サイズもバラバラでした。
今回は、特定の値に統一してみようと思います。
*追記*
実験当時は知りませんでしたが、YOLOでは416px×416pxが基本で、少なくとも32の倍数の正方形になるようにリサイズが推奨されています。
③学習データ数を増やす
画像認識では、1カテゴリーに1000枚程度の画像を学習させるのが一般的のようです。
前回は、10枚程度で学習していました→認識率低くて当然ですね。。(笑)
今回、1000枚は無理ですが、とりあえず実験として25枚程度と枚数を増やし、①の通り、画像の質も上げてみることにしました。
実行環境

[PC]
OS:Windows10
CPU:Core i7
メモリ:16GB
GPU:GTX
[Python]
Python 3.9.7
anaconda 4.10.3
※このあとインストール
せっかくなので、手順もしっかり記載しておきます。
流れはこんな感じです。
【目次】
①anacondaのインストール
②開発環境の準備
③学習済みモデルで一度実験する(環境の確認)
④画像を用意する
⑤アノテーションをする
⑥学習前の準備
⑦学習の実行
⑧結果の確認
⑨反省と今後の改善点
では、早速いきましょうー!
① anacondaのインストール
複雑な環境構築をこれだけで出来てしまう、ほんと頭が上がらないほど便利なツールです。
https://www.anaconda.com/ -Anaconda公式サイト
GetStarted → Down Load Anaconda Installers からご自身のPC環境に合わせてダウンロードします。
exeファイルを起動しインストールを実行してください。
② 開発環境の準備
Anaconda Prompt(Anaconda3)を立ち上げます。
おそらくWindows自体の検索窓にて、Anaconda Prompt(Anaconda3)を検索すると出てきます。
こんな真っ黒な画面が出てきます。
Anacondaでは、仮想環境を作ることが出来ます。
「難しそうに聞こえますが、簡単ですので、順番に進めてみてください。

ここで、次のコードを入力します。
conda create -n yolo_v3Proceed ([y]/n)?が表示された場合は、yを押してください。
これで、anaconda上に仮想環境が作られました。
作った仮想環境をアクティベート(使える状態にすること)していきます。
conda activate yolo_v3左の(base)が(yolo_v3)に変われば成功です!
次に、必要なライブラリをインストールしていきます。
YOLOを使うために、必要なツールのことです。
クックドゥがYOLOとしたら、鍋や火、具材にあたります。
- Tensorflow
- Keras
- Matplotlib
- Pillow
- h5py :2.10.0
conda install tensorflow==1.14.0 keras==2.2.4 pillow matplotlibYOLO3を使用する際、h5pyはバージョン指定が必須です。
h5pyはkerasインストール時に一緒にインストールされますが、おそらくバージョンが異なっていると思います。
機械学習ではバージョンにより動作しないことが多くあります。
重要なところなので、しっかり確認しておきます。
conda list h5pyこれで、Version 2.10.0と表示されていればOKです。
なっていない場合は、一度アンインストールしてから再度バージョン指定でインストールします。
pip uninstall h5pypip install h5py = 2.10.0下記のコードで、もう一度確認してみて、Versionが合っていれば成功です。
conda list h5pyAnaconda Promptは、このまま一旦置いておきましょう。
開発環境の構築は、あと1ステップです!
物体検知で有名なYOLOをダウンロードします。
本当に素晴らしいアルゴリズムなので、お力をお借りします。
ダウンロードしたZIPファイルは解凍後、デスクトップに置きます。
https://github.com/qqwweee/keras-yolo3 -github YOLOのダウンロード
これで開発環境は完成しました。
ここから実際に学習させて、物体検知を行うのですが、
しっかり環境構築が出来ているか確認しておきます。
③ 学習済みモデルで一度実験する
過去に学習済みのモデルを利用して、動作確認を行います。
下記のリンクからダウンロードします。
https://pjreddie.com/media/files/yolov3.weights -学習済みモデル
ダウンロードしたファイルは、先ほどデスクトップに解凍したkeras-yolo3-masterフォルダへ保存してください。
保存出来たら、先ほど一旦置いてあったAnaconda Promptへ戻りましょう。
まずは、ディレクトリを移動する記述をします。
cd Desktop\keras-yolo3-masterダウンロードしたweightをkerasで使えるようにコンバートしていきます。
これにより学習済みモデルが使える状態になります。
以下のコードを入力してください。
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5model_dataディレクトリにyolo.h5が保存されていればOKです。
ここから物体検知に入ります!!楽しみです♪
人、車、犬、猫などが写っている画像を用意しましょう。
私は、フリー素材より下記の画像をお借りしました。

ここでは、street.jpgという名前で保存しました。
「これを物体検知してみる!」と決めた画像を、keras-yolo3-masterフォルダの直下に入れてください。
フォルダに入れたら、Anaconda Promptへ下記コードを入れてYOLOv3を起動しましょう!
python yolo_video.py --imageすると、何やらズラーと長い文章が出てきます。
しばらく待っていると、
とInput image filename: と出てきますので、:のあとに先ほど保存した名前を入力しましょう。
Input image filename:street.jpg結果が出力されたら、成功です!!
ここから、いよいよ独自のモデルで物体検知してみようと思います。
④ 画像を用意する
まずはきのこの山とたけのこの里を購入してきましょう!!
食べたくなるのを抑えながら、写真を撮影していきます。
冒頭で説明した前回の反省をもとに、学習後に実際に使うことを想定した画像の用意を意識しました。
白背景、黒背景、木目調…など、こんなところで撮るかな~と考えながら撮影しました。






上記のように、それぞれ25枚程度を用意しました。
ただ、iPhoneで撮影したのですが、縦横比がバラバラになってしまいました。
ここでも前回の反省をもとに、画像のサイズをしっかり合わせるをしていきます。
今回は427px × 327pxに統一しました。
*追記*本当は412×412が推奨とのことです。
⑤ アノテーションしていく
機械学習で「教師あり学習」を行う場合は、機械学習のモデルとしての教師データ(正解のデータやラベルなど)を作成していきます。これをアノテーションと呼びます。
「ここにあるのがきのこの山だよ~」とタグ付けしていくイメージですね。
アノテーションには”labelimg”というソフトを使用します!
下記よりダウンロードが可能です。
ダウンロードしたら、解凍してデスクトップに配置します。
配置後、exeファイルを実行すると、次のような画面が開きます。

それでは、アノテーションしていきます!
①画像の入っているファイルを開きます
②Wキーを押して、バウンディングボックスで食品の部分を囲みます
③Labelを入力します。(ここではKinokoYamaとしました)
④画像ごとにSaveをクリックして、XML形式で保存します。
※このとき必ず画像の名前と同じ名前で保存してください。
上記④工程を、たけのこの里も含めて全画像で行います。
⑤ 学習前の準備
学習まであと少しというところまできました。
残り4ステップを進めていきます。
①ファイルに保存する
まずは、新しいフォルダを作成し、アノテーションしたファイルと元画像を移動します。
フォルダ名を間違えないようにしてください
”VOCdevkit” , “VOC2007” , “Annotations” , “ImageSets” , “JPEGImages”。

画像とアノテーションしたファイルを指定の場所に移動したら、下記3つのテキストファイルを作成します。
train.txt →学習に用いるファイル
val.txt →検証に用いるファイル
test.txt →学習に用いないテストファイル
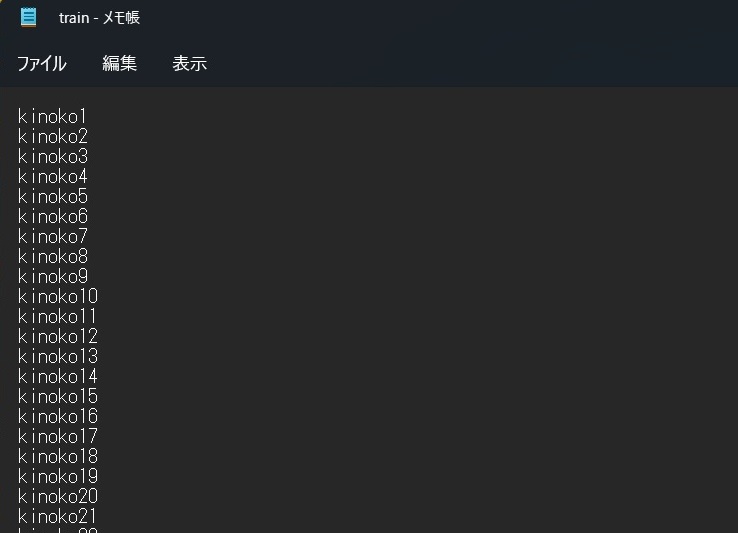
train.txt
①拡張子.jpgを除いたファイル名を列挙します。
②最後の行も改行してください →エラーになります
val.txt
このテキストファイルには、何も記入しません。
空の状態で保存します。
test.txt
①テスト用に、train.txtに列挙していない画像を列挙します。
(きのこの山とたけのこの里でそれぞれ数枚でOK)
②拡張子.jpgを除いたファイル名で列挙します。
③最後の行も改行してください →エラーになります
これらファイルは、ImageSet→Mainフォルダ内に配置します。
②アノテーションファイルを生成する
keras-yolo3-masterフォルダ下にあるvoc_annotation.pyをワードパットなどで開きます。
6行目付近にある一文を下記のように書き換えて保存します。
classes = ["KinokoYama", "TakenokoSato"]YOLOv3実行環境をアクティベートします。
AnacondaPromptを開きアクティベート後、作業ディレクトリへ移動してください。
次のコードを実行します。
conda activate yolo_v3
cd Desktop\keras-yolo3-master準備が整いましたら↓コードを実行してアノテーションファイルを生成します。
python voc_annotation.py実行後にkeras-yolo3-masterフォルダ下に下記3つのテキストファイルが生成されればOKです。
- 2007_train.txt
- 2007_val.txt
- 2007_test.txt
AnacondaPromptはこのままにしておきます。
③コードを書き換える
☆voc_classes.txtの書き換えをします。
keras-yolo3-master/model_data下にあるvoc_classes.txtの中身を変更します。
”aeroplane”、”bicycle”…と色々書いてありますが全部削除し、
KinokoYama
TakenokoSato
と記入し、ファイル名は”my_classes.txt“で名前をつけて保存してください。
☆train.pyの書き換えをします。
keras-yolo3-masterフォルダ下にあるtrain.pyをワードパットなどで開きます。
17行目を次のように変更します。
annotation_path = ‘2007_train.txt’さらに19行目を変更します。
classes_path = ‘model_data/my_classes.txt’さらにbatch_sizeを変更していきます。
57行目あたりと81行目あたりを次のように書き換えます。
atch_size = 8変更が完了しましたら、上書き保存して閉じてください。
☆weightのコンバートをする
下記をAnacondaPromtで実行します。
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5これにて準備完了です!
⑥ 学習させる
下記を実行して、学習を開始させます。
PCの性能により、かなり時間がかかります。
python train.pyひたすた待ちます!!
keras-yolo3-master/logs/000/下にファイルが生成されれば学習が完了となります。
このファイルがきのこの山とたけのこの里の学習モデルです。
⑥ 結果を確認する
結果確認の前に、少しだけ変更箇所があります。
☆yolo.pyの書換え
keras-yolo3-masterフォルダ下にあるyolo.pyをワードパットなどで開きます。
23行目を変更します。
“model_path”: ‘logs/000/trained_weights_final.h5’,さらに25行目を変更します。
“classes_path”: ‘model_data/my_classes.txt’,変更が出来たら上書き保存します。
AnacondaPromptに下記を入力して実行します。
python yolo_video.py --image最後に”Input image filename:”が表示されるので、ここに学習へ使用していないたけのこの里ときのこの山の画像の名前を入れます。
Input image filename:*****.jpg結果画像が自動で表示されました!

やや誤認識もありました、、、(´;ω;`)
次の記事では、この実験をもとに物体検知の仕組みをもとに精度の分析を行っていきます。
なお、実験には下記の記事を参考にさせていただきました。
この場をお借りして感謝いたします。
https://farml1.com/snackpea_1/
